c++反汇编揭秘
4. 观察各种表达式的求值过程
4.1 加法
release版
|
|
ida
|
|
|
|
4.2 减法
release版
|
|
ida
|
|
|
|
4.3 乘法
release
|
|
ida
|
|
|
|
4.4除法
常用指令
- cdq:把eax的最高位填充到edx,如果
eax ≥ 0,edx = 0,如果eax < 0,edx = 0xFFFFFFFF - sar:算术右移
- shr:逻辑右移
- neg:将操作数取反+1
- div:无符号数除法
- idiv:有符号除法
- mul:无符号数乘法
- imul:有符号数乘法
4.5 取模
release
|
|
ida
|
|
|
|
总结:
- 第一种对2的k次方取余:
and eax,80000007h,去掉最高位保留低位,统计低位一个保留了多少1(7的二进制位0111,保留了3个1),即可得到k的值为3,然后得到结果:2^3 = 8 - 第二种对非2的k次方求余:
[eax+eax*8] = eax*9,即可得到结果9
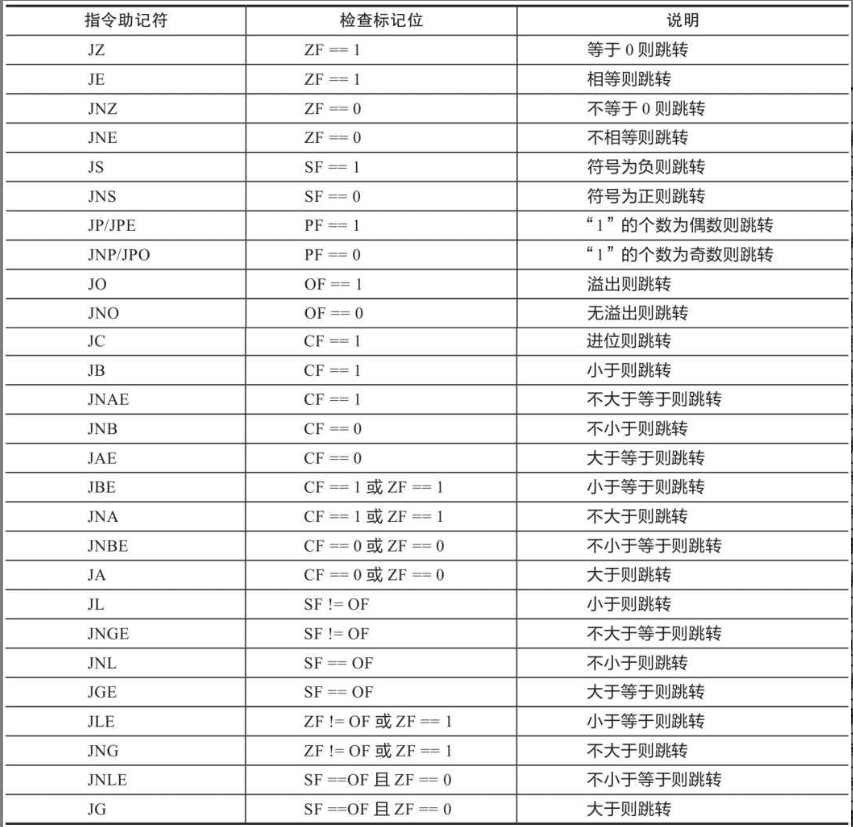
4.6 条件跳转指令表
4.7 条件表达式
4.7.1 相差为1
release
|
|
ida
|
|
|
|
4.7.2 相差大于1
release
|
|
ida
|
|
|
|
4.7.3 变量表达式
release
|
|
ida
|
|
|
|
4.7.4 表达式无优化使用分支
release
|
|
ida
|
|
|
|
5. 流程控制语句的识别
5.1 if语句
release
|
|
ida
|
|
|
|
通过汇编可以发现,if语句转换的条件跳转指令与if语句的判断结果是相反的。
根据这一特性,如果将if语句中的比较条件argc == 0修改为if(argc > 0),则其对应的汇编语言使用的条件跳转指令会是“小于等于0”。
release
|
|
ida
|
|
|
|
总结:

5.2 if else语句
release
|
|
ida
|
|
|
|
5.3 switch语句
5.3.1 分支少于4个
release
|
|
ida
|
|
|
|
5.3.2 分支大于4个且值连续
会对case语句块制作地址表,以减少比较跳转次数
release
|
|
ida
|
|
|
|
5.3.3 分支大于4个,值不连续,且最大case值和case值的差小于256
有两张表
- case语句块地址表:每一项保存一个case语句块的首地址,有几个case就有几项,default也在里面。
- case语句块索引表:保存地址表的编号,索引表的大小等于最大case值和最小case值的差。
release
|
|
ida
|
|
|
|
5.3.4 分支大于4个,值不连续,且最大case值和case值的差大于256
将每个case值作为一个节点,找到这些节点的中间值作为跟节点,形成一颗平衡二叉树,以每个节点作为判定值,大于和小于关系分别对应左子树和右子树。
release
|
|
ida
|
|
|
|
5.4 do while语句
release
|
|
ida
|
|
|
|
5.5 while语句
release
|
|
ida
|
|
|
|
5.6 for语句
release
|
|
ida
|
|
|
|
6. 函数的工作原理
6.1 栈帧的形成和关闭
栈在内存中是一块特殊的存储空间,它的存储原则是“先进后出”,即最先被存储的数据最后被释放。汇编过程通常使用PUSH指令与POP指令对栈空间执行数据压入和数据弹出的操作。
栈结构在内存中占用一段连续的存储空间,通过esp和ebp这两个栈指针寄存器保存当前栈的起始地址与结束地址(又称为栈顶与栈底)。在32位程序的栈结构中,每4字节的栈空间保存一个数据;在64位程序的栈结构中,每8字节的栈空间保存一个数据。像这样的栈顶到栈底之间的存储空间被称为栈帧。
栈帧是如何形成的呢?当栈顶指针esp小于栈底指针ebp时,就形成了栈帧。通常,在C++中,栈帧可以寻址局部变量、函数返回地址、函数参数等数据。
不同的两次函数调用,形成的栈帧也不相同。当一个函数调用另一个函数时,就会针对调用的函数开辟所需的栈空间,形成此函数的栈帧。当这个函数结束调用时,需要清除它使用的栈空间,关闭栈帧,我们把这一过程称为栈平衡。
如果某一函数开辟了新的栈空间后没有进行恢复,或者过度恢复,就会造成栈空间上溢或下溢,极有可能给程序带来致命错误。
6.2 各种调用方式的考察
C++环境下的调用约定有3种:
- _cdecl:C\C++默认的调用方式,调用方平衡栈,不定参数的函数可以使用这种方式。(外平栈,按从右至左的顺序压参数入栈)
- _stdcall:被调方平衡栈,不定参数的函数无法使用这种方式。(内平栈,按从右至左的顺序压参数入栈)
- _fastcall::寄存器方式传参,被调方平衡栈,不定参数的函数无法使用这种方式。(前两个参数用ecx和edx传参,其余参数通过栈传参方式,按从右至左的顺序压参数入栈)
当函数参数个数为0时,无须区分调用方式,使用_cdecl和_stdcall都一样。而大部分函数都是有参数的,通过查看平衡栈即可还原对应的调用方式。我们通过代码清单6-1分析_cdecl与_stdcall这两种调用方式的区别。
6.3 函数的参数
release
|
|
ida
|
|
|
|
7. 变量在内存中的位置和访问方式
变量的作用域
- 全局变量:属于进程作用域,整个进程都能够访问到
- 静态变量:属于文件作用域,在当前源码文件内可以访问到
- 局部变量:属于函数作用域,在函数内可以访问到
7.1 全局变量和局部变量的区别
全局变量和局部变量的区别
- 全局变量:可以在程序中的任何位置使用
- 局部变量:局限于函数作用域内,若超出作用域,则由栈平衡操作释放局方局部变量的空间
- 局部变量:通过申请栈空间存放,利用栈指针ebp或esp间接访问,其地址是一个未知可变值
- 全局变量:与常量类似,通过立即数访问
7.2 局部静态变量的工作方式
局部静态变量
- 存放在静态存储区
- 作用域:所定义的函数
- 生命周期:持续到程序结束
- 只初始化一次
release版
|
|
ida
|
|
|
|
7.3 堆变量
- 使用malloc和new申请堆空间,返回的数据是申请的堆空间地址
- 使用free和delete释放堆空间
release
|
|
ida
|
|
|
|
8. 数组和指针的寻址
8.1 数组在函数内
在函数内定义数组
- 去其它声明,该数组即为局部变量,拥有局部变量的所有特性
- 数组名称表示该数组的首地址
- 占用的内存空间大小为:sizeof(数据类型)x数组中元素个数
- 数组的各元素应为同一数据类型,以此可以区分局部变量与数组
字符数组初始化为字符串
release
|
|
ida
|
|
|
|
8.2 数组作为参数
8.2.1 strlen()函数
release
|
|
ida
|
|
|
|
8.2.2 strcpy()函数
在字符串初始化时,利用xmm寄存器初始化数组的值,一次可以初始化16字节,效率更高。
release
|
|
ida
|
|
|
|
8.3 存放指针类型数组的数组
release
|
|
ida
|
|
|
|
8.4 函数指针
release
|
|
ida
|
|
|
|
9. 结构体和类
9.1 对象的内存布局
- 空类
空类的长度位1字节
- 内存对齐
结构体中的数据成员类型最大值为M,指定对齐值为N,则实际对齐值为q=min(M,N)
- 静态数据成员
类中的数据成员被修饰为静态时,它与局部静态变量类似,存放的位置和全局变量一致
9.2 this指针
对象调用成员的方法以及取出数据成员的过程
- 利用寄存器ecx保存对象的首地址
- 以寄存器传参的方式将其传递到成员函数中
debug
|
|
ida
|
|
|
|
9.3 对象作为函数参数
debug
|
|
ida
|
|
|
|
含有数组数据成员的对象传参
debug
|
|
ida
|
|
|
|
9.4 对象作为返回值
debug
|
|
ida
|
|
|
|
10. 构造函数和析构函数
根据生命周期将对象进行分类,分析各类对象构造函数和析构函数的调用时机
- 局部对象
- 堆对象
- 参数对象
- 返回对象
- 全局对象
- 静态对象
10.1 构造函数的出现时机
10.1.1 局部对象
debug
|
|
ida
|
|
|
|
总结:局部对象构造函数的必要条件
- 该成员函数是这个对象在作用域内调用的第一个成员函数,根据this指针可以区分每个对象
- 这个成员函数通过thiscall方式调用
- 这个函数返回this指针
10.1.2 堆对象
debug
|
|
ida
|
|
|
|
总结:
- 使用new申请堆空间之后,需要调用构造函数来完成对象数据成员的初始化
- 如果堆空间申请失败,则不调用构造函数
- 如果new执行成功,返回值是对象的首地址
- 识别堆对象的构造函数:重点分析new的双分支结构,在判定new成功的分支迅速定位并得到构造函数
10.1.3 参数对象
当对象作为函数参数时,会调用赋值构造函数
debug
|
|
ida
|
|
|
|
10.1.4 返回对象
返回对象与参数对象类似,都会使用赋值构造函数。但是,两者使用时机不同
- 当对象为参数时,在进入函数前使用赋值构造函数
- 返回对象则在函数返回时使用赋值构造函数
debug
|
|
ida
|
|
|
|
10.2 析构对象的出现时机
10.2.1 局部对象
重点考察作用域的结束处,当对象所在作用域结束后,将销毁作用域所有变量的栈空间,此时便是析构函数出现的时机。析构函数同样属于成员函数,因此在调用的过程中也需要传递this指针。
debug
|
|
ida
|
|
|
|
10.2.2 堆对象
用detele释放对象所在的空间,delete的使用便是找到堆对象调用析构的关键点
debug
|
|
ida
|
|
|
|
11. 虚函数
对于具有虚函数的类而言,构造函数和析构函数的识别过程更加简单。而且,在类中定义虚函数后,如果没有提供
构造函数,编译器会生成默认的构造函数。
对象的多态需要通过虚表和虚指针完成,虚表指针被定义在对象首地址处,因此虚函数必须作为成员函数使用。
11.1 虚函数的机制
当类中定义有虚函数,编译器会将给类中所有虚函数的首地址保存在一张地址表,这张表被称为虚函数地址表,简称虚表。同时还会在类中添加一个隐藏数据成员,称为虚表指针,该指针保存虚表的首地址,用于记录和查找虚函数。
11.1.1 默认构造函数初始化虚表指针的过程
- 没有编写构造函数时,编译器默认提供构造函数,以完成虚表指针的初始化
- 虚表中虚函数的地址排列顺序:先声明的虚函数的地址会被排列在虚表靠前的位置
- 第一个被声明的虚函数的地址在虚表的首地址处
debug
|
|
ida
|
|
|
|
11.1.2 调用自身类的虚函数
直接通过对象调用自身的成员虚函数,编译器使用了直接调用函数方式,没有访问虚表指针,而是间接获取虚函数地址。
debug
|
|
ida
|
|
|
|
11.1.3 析构函数分析
执行析构函数时,实际上是在还原虚表指针,让其指向自身的虚表首地址,防止在析构函数中调用虚函数时取到非自身虚表,从而导致函数调用错误。
debug
|
|
ida
|
|
|
|
11.2.虚函数的识别
判断是否为虚函数
- 类中隐式定义了一个数据成员
- 该数据成员在首地址处,占一个指针大小
- 构造函数会将此数据成员初始化为某个数组的首地址
- 这个地址属于数据区,是相当固定的地址
- 在这个数组中,每个元素都是函数地址
- 这些函数被调用时,第一个参数是this指针
- 在这些函数内部,很有可能堆this指针使用间接的访问方式
12. 从内存角度看继承和多重继承
12.1 识别类与类之间的关系
debug
|
|
ida
|
|
虚函数的调用过程是间接寻址方式:
debug
|
|
ida
|
|
|
|
12.2 多重继承
debug
|
|
ida
|
|
|
|
通过反汇编分析,sofabed对象前4个字节保存SofaBed_1的虚表,再之后的4个字节保存Sofa的成员变量color,再之后的4个字节保存vfptr_SofaBed_2的虚表,之后就是Bed的两个成员变量:length、width;最后4个字节保存SofaBed成员变量height,所以对象的大小为24字节。
单继承类和多重继承类特征总结
单继承
- 在类对象占用的内存空间中,只保存一份虚表指针。
- 因为只有一个虚表指针,所以只有一个虚表。
- 虚表中各项保存了类中各虚函数的首地址。
- 构造时先构造父类,再构造自身,并且只调用一次父类构造函数。
- 析构时先析构自身,再析构父类,并且只调用一次父类析构函数
多重继承
- 在类对象占用内存空间中,根据继承父类(有虚函数)个数保存对应的虚表指针。
- 根据保存的虚表指针的个数,产生相应个数的虚表。
- 转换父类指针时,需要调整到对象的首地址。
- 构造时需要调用多个父类构造函数。
- 构造时先构造继承列表中的第一个父类,然后依次调用到最后一个继承的父类构造函数。
- 析构时先析构自身,然后以构造函数相反的顺序调用所有父类的析构函数。
- 当对象作为成员时,整个类对象的内存结构和多重继承相似。当类中无虚函数时,整个类对象内存结构和多重继承完全一样,可酌情还原。当父类或成员对象存在虚函数时,通过观察虚表指针的位置和构造、析构函数中填写虚表指针的数目、顺序及目标地址,还原继承或成员关系。
12.3 抽象类
debug
|
|
ida
|
|
|
|
在抽象类的虚表信息中,因为纯虚函数没有实现代码,所以没有首地址,编译器为了防止误调用虚函数,将虚表中保存的纯虚函数的首地址项替换成函数__purecall,用于结束程序。在分析过程中,一旦在虚表中发现函数地址为__purecall函数时,就可以高度怀疑此虚表对应的类是一个抽象类。